「YouTube動画に字幕をつけたいけれど、手動入力にかかる時間を考えると気が重くなる」そんな悩みを抱えているYouTube運営者は多いのではないでしょうか。
この記事では、OpenAIが公開したAI音声認識ツール「Whisper」を使って、動画の字幕を自動で作る方法を紹介します。プログラミングの知識は必要なく、コマンドを1行入力するだけで、タイムコード付きのSRT字幕ファイルが手に入ります。
さらに、ゆっくり解説系動画でおなじみのYMM4(ゆっくりムービーメーカー4)に、そのSRTを取り込む手順もあわせてお伝えします。インストールから字幕完成まで、初心者でも迷わないよう順を追って解説しますので、安心して読み進めてください。
Whisperとは?YouTube運営者が注目すべき理由
Whisperは、OpenAIが無償公開したAI音声認識ツールです。動画の音声を自動でテキスト化でき、YouTube運営者にとって字幕作業の負担を大きく減らせます。ここでは、Whisperの特徴と注目される理由を順番に見ていきましょう。
Whisperは「AI音声認識ツール」
Whisperは、OpenAIが2022年に公開した音声認識モデルです。音声をテキストへ変換する処理を、手元のPCだけで完結できる点が最大の特徴といえるでしょう。
学習データの規模も大きく、68,000時間を超える多言語音声で訓練されたモデルになっています。背景ノイズや専門用語にも強く、実用レベルの精度を発揮する理由はここにあります。
使い方は非常にシンプルで、動画ファイル(MP4)を渡すだけでタイムコード付きのSRTファイルを自動生成してくれます。YouTube動画の音声を文字起こしして字幕ファイルとして書き出す用途にとても向いているツールです。詳しい技術情報はOpenAIの公式ページで確認できます。
無料・高精度・日本語対応の三拍子
Whisperには、ローカル環境で動かせば完全無料、しかも精度が高く、約100言語に対応しているという三つの強みがあります。商用動画に使う場合でも、追加のライセンス料などは発生しないため、YouTube運営者にとって導入のハードルが低い点も魅力です。
無料で使える理由は、MITライセンスのオープンソースとして公開されているからです。個人利用だけでなく商用利用も明確に許諾されており、収益化を狙うチャンネルでも安心して取り入れられます。
精度についても注目してほしいポイントがあります。OpenAI公式の解説によれば、Fleurs評価でlarge-v2モデルが日本語で5.3という良好なスコアを記録しました(スペース区切りのない日本語は実質CERに近い評価です)。
モデルサイズを柔軟に選べる点もメリットのひとつです。tiny(最軽量・低精度)、base、small、medium(精度と速度のバランスが良い)、large(最高精度)、turbo(高速かつ高精度)の6種類が用意されており、PCスペックに合わせて切り替えられます。日本語音声であれば、mediumクラス以上を選んでおくと安心です。
事前準備|必要なものを確認しよう
Whisperを使うために用意するものは、実はとてもシンプルです。Python、FFmpeg、pipの3つさえ整えておけば、インストールから字幕生成までスムーズに進められます。ここでは、それぞれの役割と準備の流れを順番に見ていきましょう。
Whisperの動作環境(Windows/Mac)
Whisperを動かすには、Python 3.8以上とFFmpegが用意されていれば、WindowsでもMacでも問題なく利用できます。Pythonのバージョンは、比較的トラブルが少ない3.10〜3.12系を選んでおくと安心でしょう。
OS依存がほぼないのは、WhisperがPythonのパッケージとして配布されているからです。Python 3.13系では依存関係にからむ問題の報告例もあるため、最新版をあえて選ばず、実績のあるバージョンを入れておく方が迷いが少なく済みます。
処理速度を重視する場合は、NVIDIAのCUDAに対応したGPUがあると大幅に短縮できます。ただし、CPUのみの環境でも動作自体は問題ありません。たとえばWindows 11、Python 3.12、CPUのみという構成でも利用できます。
処理時間はPCのスペックとモデルサイズに左右されるため、いきなり大きいモデルを使うより、まずはtinyやbaseのような小さいモデルで試してから、少しずつサイズを上げていくのがおすすめです。
FFmpegが正しく導入できているかは、コマンドプロンプトで ffmpeg -version を実行すれば確認できます。詳しい環境構築の手順はPC環境構築の解説もあわせて参考になります。
PythonとWhisperのインストール手順(コピペで完結)
インストールの流れは3つのステップに整理できます。
- Python 3.10〜3.12をインストール
- FFmpegをインストール
- コマンドプロンプトで
python -m pip install -U openai-whisperを実行
この3つを順番に進めれば環境が整います。
Whisperの本体は、PyPIというPythonのパッケージ管理サービス上で配布されているため、pipコマンド1行でインストールできるしくみになっています。FFmpegは動画ファイルを読み込むために必須の依存ライブラリで、これがないと音声の抽出ができません。
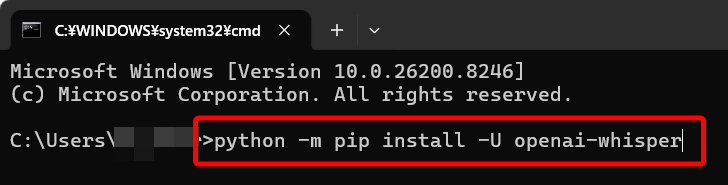
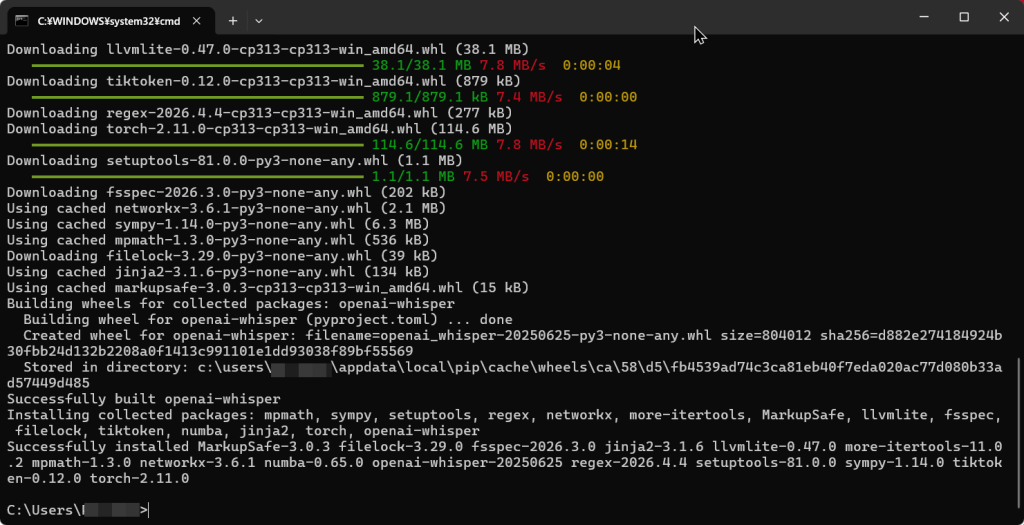
実際のコマンドは python -m pip install -U openai-whisper です。-U オプションを付けると、すでに古いバージョンが入っていた場合も最新版へ更新できます。
Pythonをインストールするときは、最初の画面で「Add Python to PATH」のチェックボックスを必ずONにしてください。このチェックを外すと、あとでコマンドが通らなくなり、初心者がつまずく一番の原因になります。
FFmpegは、Windows環境であれば winget install ffmpeg というコマンドでも導入できます。入れ終わったら ffmpeg -version でPATHの確認までセットで済ませておくと、後からのトラブルを防ぎやすくなります。インストール全体の流れはWhisper CLIの解説記事でも詳しく紹介されています。
Whisperで字幕ファイルを作る手順
準備ができたら、いよいよ字幕ファイルの作成です。Whisperはコマンドラインで動くツールなので、コマンドプロンプトに1行入力するだけで文字起こしが始まります。ここでは、動画ファイルの用意から出力の確認まで、3つのステップで順番に見ていきましょう。
STEP1|動画ファイルを用意する
まず最初に、文字起こしをしたい動画ファイルを手元に用意します。Whisperが対応しているのはMP4・WAV・M4A・MP3など主要な動画・音声形式で、YouTube用に書き出した動画であればほとんどのケースで読み込めます。
ファイル形式の対応範囲が広い理由は、WhisperがFFmpegを経由してファイルを読み込む設計になっているからです。つまり、FFmpegが扱える形式であれば、Whisper側でも基本的に動作します。
ただし、初回の実行時はファイルの置き場所に少し気をつけてください。日本語を含むフォルダ名や長すぎるファイル名は、引用符で囲うことで通るケースもありますが、最初のうちは短い半角英数字のフォルダを使うほうが安定しやすいです。
具体的には C:\whisper_work\video.mp4 のように、浅い階層に英数字だけのフォルダを用意しておくと迷いません。YouTubeの動画を書き出したら、このフォルダへコピーする習慣をつけておくと、毎回ファイルの置き場所を考えずに済ませられるでしょう。詳しい使い方はGitHubの公式リポジトリも参考になります。
STEP2|コマンドを1行入力して実行する
※実行をすると、指定したモデルのダウンロードが始まります。mediumは約1.4GBありました

動画ファイルを用意できたら、コマンドプロンプトを開いて、1行コマンドを入力するだけで文字起こしが始まります。基本の形は whisper " です。ファイル名と言語、モデルの3つを指定するシンプルな構成になっています。C:\whisper_work\video.mp4" --language ja --model medium
コマンドの中で --language ja を明示している点には意味があります。言語を指定しないと自動検出が働くのですが、日本語動画でもまれに英語と判定されてしまい、誤認識が増える原因になりやすいのです。最初から ja を付けておくと、この種のミスを防げます。
--model のオプションはtiny、base、small、medium、large、turboの6種類から選べます。医療や技術用語が多い動画、複雑なボイスが入った動画では、mediumかそれ以上を指定すると精度が上がりやすい傾向があります。
実際に使うフルコマンドの一例は whisper C:\whisper_work\video.mp4 --language ja --model medium --output_format srt です。--output_format srt を追加すれば、出力がSRT形式だけに絞られ、不要なファイルで作業フォルダが散らからずに済みます。コマンドオプションの詳しい解説はWhisperで字幕ファイルを自動作成する記事も参考になります。
STEP3|出力されたファイルを確認する
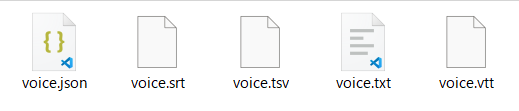
コマンドの実行が終わると、動画ファイルと同じフォルダにtxt、vtt、srt、tsv、jsonの5種類のファイルが自動で作られます。YMM4に取り込むときに使うのは、この中のSRTファイルです。
Whisperは既定の動作で、これら複数のフォーマットを同時に書き出します。SRTは「連番・開始時刻→終了時刻・テキスト」という決まった構造で書かれた、字幕業界の標準フォーマットです。動画プレーヤーや編集ソフトの多くが対応しているため、汎用性が高い点も便利といえます。
生成後は、必ずSRTの中身を一度確認してください。Whisperの認識精度は高いものの、固有名詞や専門用語などで誤変換が起こる場合もあります。VS CodeなどUTF-8対応のテキストエディタで開いて、おかしな箇所を手直ししてからYMM4に読み込ませると、完成度の高い字幕に仕上がります。
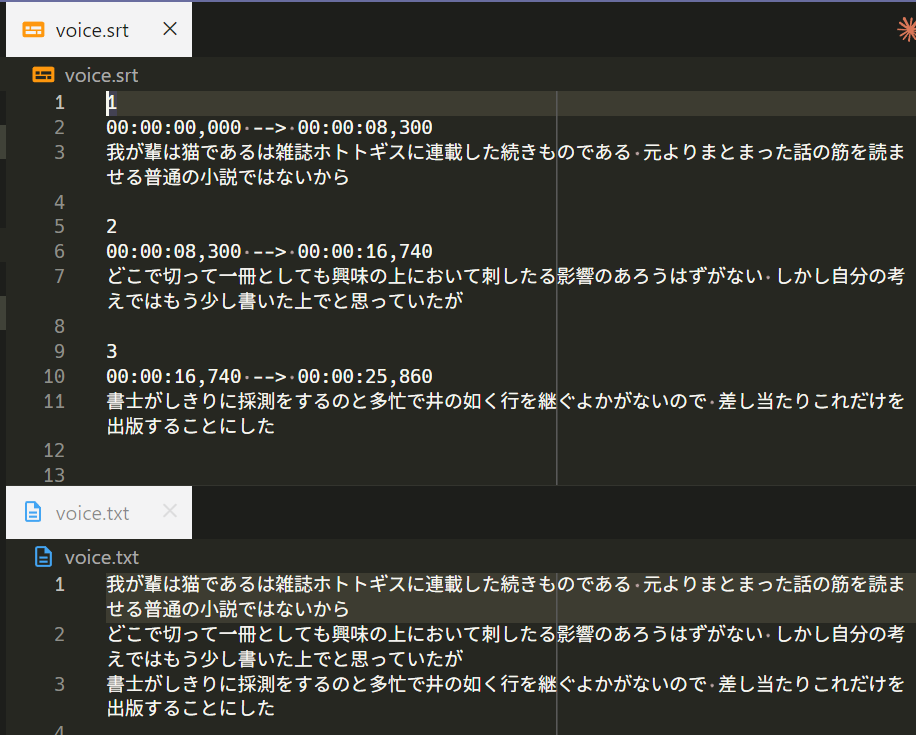
たとえば video.srt がタイムコード付きの字幕、video.txt がタイムコードなしの全文テキストとして書き出されるイメージです。両方を見比べながら編集すると、流れのある字幕に整えやすくなります。
出力ファイルをYMM4に取り込む方法
SRTファイルが用意できれば、あとはYMM4に読み込ませるだけで字幕作業は一気に楽になります。YMM4 v4.25からはSRTを直接インポートできる機能が追加されたため、面倒な変換作業も不要です。ここでは、具体的な取り込み方法を見ていきましょう。
SRTファイルをYMM4用CSVに変換する
以前は、SRTを直接YMM4に読み込ませることができず、わざわざCSV形式に変換する手間がかかっていました。ただ、YMM4 v4.25以降のバージョンを使っているなら、CSV変換の手順はもう必要ありません。現在はSRTのまま放り込めばよくなり、ずいぶんと手数が減りました。
もし古いバージョンを使っていて、どうしてもCSV台本を作る必要がある場合は、A列にキャラクター名、B列にセリフを並べる形式で作成します。保存時の文字コードは「UTF-8(コンマ区切り)」を選んでください。文字コードを間違えると文字化けが発生するので、この一点だけは注意が必要です。
ただ、最新版のYMM4が手元にある人は、この項目は読み飛ばしてしまって問題ありません。SRTを直接インポートするほうが、手順がすっきりしていて時間も短く済みます。
YMM4で字幕として読み込む手順
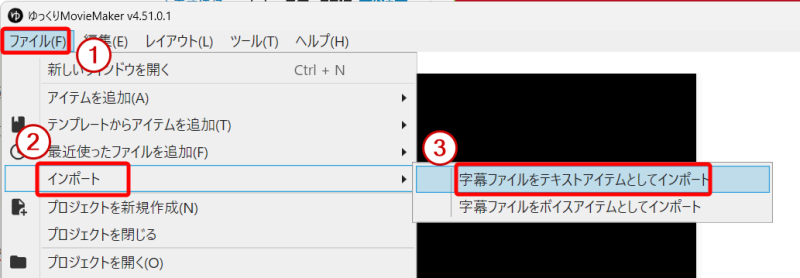
SRTを直接YMM4へ取り込む流れは、とてもシンプルです。メニューから「ファイル」→「インポート」→「字幕ファイルをテキストアイテムとしてインポート」を選んで、生成したSRTファイルを指定するだけ。これだけでタイムライン上にテキストアイテムが自動配置されます。
この自動配置ができるのは、インポート機能がSRT内のタイムコードを読み取り、各字幕ブロックを対応する時刻に並べてくれるためです。手動でタイミングを合わせる必要がなく、字幕作業の時間短縮に大きく貢献します。

操作の流れを具体的にまとめると、次のとおりです。まずYMM4を起動してプロジェクトを開きます。続いてメニューバーから「ファイル」→「インポート」→「字幕ファイルをテキストアイテムとしてインポート」と順にクリックし、STEP3で生成したSRTファイルを指定してください。最後に、タイムライン上にテキストアイテムが追加されていることを確認すれば完了です。
メニュー操作だけでなく、SRTファイルをタイムラインへドラッグ&ドロップする方法でも取り込めます。
1
00:00:00,000 --> 00:00:08,300
>> 四国めたん: 我が輩は猫であるは雑誌ホトトギスに連載した続きものである 元よりまとまった話の筋を読ませる普通の小説ではないから
2
00:00:08,300 --> 00:00:16,740
>> 四国めたん: どこで切って一冊としても興味の上において刺したる影響のあろうはずがない しかし自分の考えではもう少し書いた上でと思っていたが
3
00:00:16,740 --> 00:00:25,860
>> 四国めたん: 書士がしきりに採測をするのと多忙で井の如く行を継ぐよかがないので 差し当たりこれだけを出版することにしたまた、SRTの行を >> キャラ名: セリフ内容 形式で書いておくと、YMM4側でボイスアイテムとして認識されるしくみもあります。単一キャラクターの場合はファイルで指定しなくても、メニューバーから「ファイル」→「インポート」→「字幕ファイルをボイスアイテムとしてインポート」で、YMM4のフッターで指定したキャラクターボイスで追加が可能です。
うまくいかないときのトラブルシューティング
Whisperを導入したときのつまずきポイントは、実はある程度パターン化されています。多くの場合、PATH設定、文字コード、モデル設定の3つが原因になっています。ここでは、それぞれのトラブルと対処方法を順番に見ていきましょう。
Pythonが認識されない場合
「’python’ は認識されていないコマンド」と表示されたら、ほとんどのケースでPATH設定が原因です。Pythonをインストールしたときに「Add Python to PATH」のチェックボックスをONにしていないと、コマンドプロンプトがPythonの場所を見つけられません。
Windows環境では、PATHに登録されていないプログラムはシステムから認識されない仕様になっています。さらにややこしいのは、コマンドプロンプトが起動時点のPATHを保持する点です。PATH設定を追加した後でも、古いコマンドプロンプトには反映されないため、必ず新しいウィンドウを開き直してから再度試す必要があります。
対処方法は大きく2つあります。1つ目は、Pythonを一度アンインストールしてから再インストールし、インストーラー最初の画面で「Add Python to PATH」にチェックを入れる方法です。
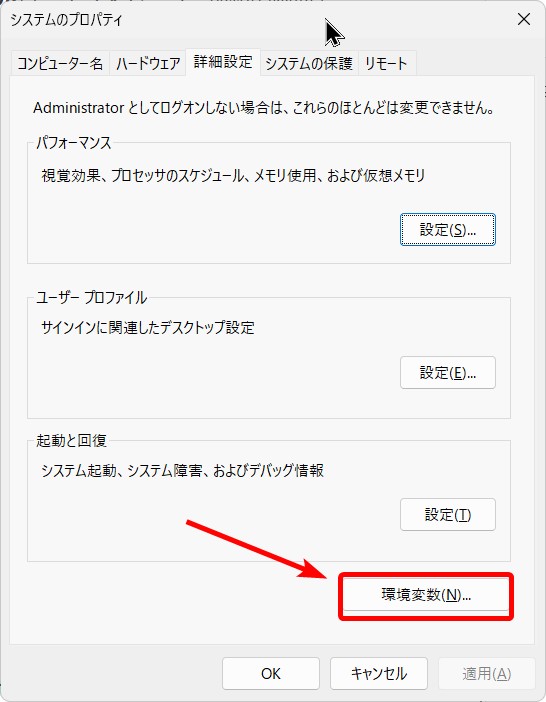
2つ目は、Windowsの「システム環境変数の編集」画面から、Pythonの実際のインストール先フォルダを手動で追加する方法です。
インストール先は環境によって変わるため、エクスプローラーで実際の置き場所を確認してから作業してください。修正できたら、新しいコマンドプロンプトを開き python --version と入力し、バージョン情報が表示されれば成功です。
日本語が文字化けする場合
端末上で日本語が文字化けしているように見える場合、実はWhisper本体の問題ではなく、端末の表示設定が原因になっていることが多いです。PowerShellなど一部のシェルでは、文字コードの違いで日本語が崩れて表示される挙動が知られています。
ここで大事なポイントは、Whisperが書き出す出力ファイルそのものはUTF-8で保存されている点です。つまり、画面に変な文字が出ていたとしても、ファイルを開けば正常な日本語が書かれているケースがほとんどなのです。まずは出力ファイルをエディタで開いて、実際の内容を確認してみてください。
具体的な確認方法としては、whisper video.mp4 --language ja --output_format txt のようなコマンドでtxtファイルを出力し、VS CodeなどUTF-8対応のテキストエディタで中身を開きます。そこで日本語が正常に表示されていれば、Whisperの出力自体には問題がないと判断できます。
どうしても端末上でも正しく表示させたい場合は、PowerShellからcmd.exe(従来型のコマンドプロンプト)に切り替えてみると改善するケースもあります。また chcp 65001 を実行してUTF-8表示モードに切り替える方法も知られています。詳しい対処例はnote記事で紹介されています。
精度が低いと感じたときの設定変更
Whisperで文字起こししたときに「認識精度がいまいち…」と感じたら、モデル設定と言語指定の2点を見直すだけで、結果が大きく変わることがあります。具体的には --model medium または --model large にサイズを上げ、あわせて --language ja を明示指定する方法です。
モデルサイズを上げると精度が改善するのは、モデルのパラメータ数が増え、複雑な音声や専門用語にも対応しやすくなるからです。また --language ja を付けないと、自動言語検出が外れて英語として処理されるケースがあり、これが精度低下の隠れた原因になっていることもあります。
変更前のコマンド例が whisper video.mp4(現行デフォルトはturbo・言語は自動検出)だとすると、変更後は whisper video.mp4 --model medium --language ja のように書き換えます。この2箇所の追加だけで、日本語の認識精度が目に見えて変わるのを体感できるはずです。
largeモデルはmediumよりさらに精度が高い一方で、処理時間が長くなる傾向があります。実環境による差はありますが、ハイスペックPCやGPUを持っているならlarge-v2やlargeを試す価値があるでしょう。詳しい比較は精度検証の記事で紹介されています。
よくある質問(FAQ)
Whisperを使い始める前によく聞かれる疑問は、大きく3つに整理できます。「本当に無料で使えるの?」「YouTube収益化動画でも問題なく使える?」「1時間の動画はどれくらいの時間で処理できる?」という内容です。どれも導入前に知っておきたいポイントなので、順番に答えていきます。
本当に無料で使えるの?
まず、無料で使えるかどうかについてです。ローカルPC上で動かすWhisperは完全に無料で、追加課金は一切ありません。ただし、OpenAIが提供するAPI版(whisper-1)を使う場合は、1分あたり約$0.006の料金が発生する点に注意してください。自分のPCに入れて使う方法であれば、ずっと無料のまま利用できます。
YouTube収益化動画でも問題なく使える?
次に、商用動画に使ってもよいかどうかです。WhisperはMITライセンスで公開されているため、YouTubeの収益化動画に使っても問題なく利用できます。動画内に「Whisperで生成」などの表記を入れる義務もありません。
1時間の動画はどれくらいの時間で処理できる?
最後に、処理時間についてです。これはPCスペックとモデルサイズにかなり依存するため、一概に「何分」とは言い切れません。
CPUのみだとmediumモデルで実時間の数倍かかることもあれば、GPU環境なら同じモデルでもかなり短縮できる場合があります。まずはtinyやbaseで試して、自分のPCだとどれくらいかかるか把握してから、本番のmediumやlargeに移ると無駄が少なくて済みます。
まとめ
WhisperとYMM4を組み合わせれば、今まで手作業で進めていた字幕入力の多くを自動化できます。無料で始められ、プログラミング知識もいらず、さらに日本語の認識精度も高いため、YouTube運営の時間短縮に大きな効果が見込めます。
2つのツールの相性が良い理由は、Whisperが出力するSRTフォーマットを、YMM4 v4.25以降が直接取り込めるようになったためです。ファイル形式の変換作業が省けることで、全体の流れがぐっとシンプルになりました。
実際の作業を振り返ると、
- 動画をwhisper_workフォルダに置く
- コマンドプロンプトで1行実行する
- 生成されたSRTを軽く修正する
- YMM4にインポートして字幕完成
の4ステップにまとまります。一度環境を整えてしまえば、2本目以降はこの手順を繰り返すだけで、毎回の字幕作業がぐっと楽になるはずです。
YMM4側はメニュー操作だけでなく、SRTファイルをタイムラインへドラッグ&ドロップする方法でも取り込めます。自分のやりやすい方法を選んでおくと、作業テンポも上がるでしょう。